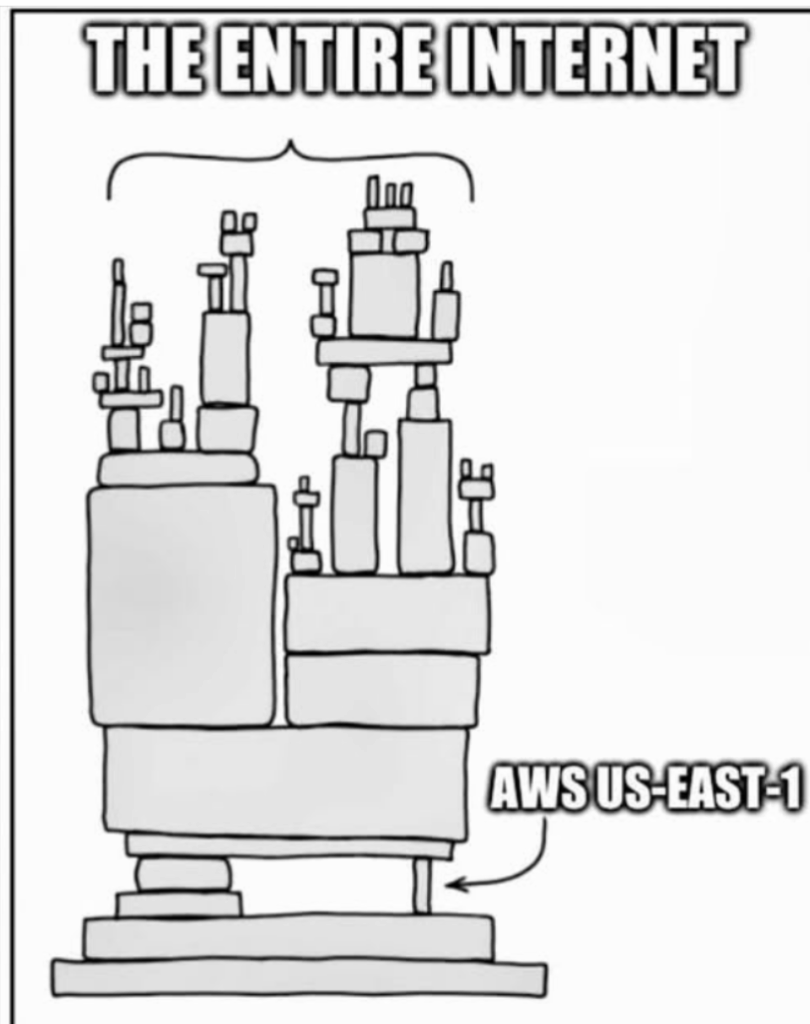
Zaczęło się niewinnie. Amazon informował o „zwiększonych opóźnieniach i błędach w usługach”, co bardzo często oznacza drobne zacięcia. Ale tym razem z drobiazgu zrobiła się globalna lawina. W ciągu godzin kolejne platformy zgłaszały problemy.
- Użytkownicy Canvy, którzy nie mogli tworzyć ani eksportować projektów graficznych
- Slack przestał wysyłać wiadomości, co skutecznie sparaliżowało komunikację w wielu firmach
- Fortnite, Roblox i Snapchat notowały problemy z logowaniem i opóźnienia w działaniu, co rozwścieczyło społeczność graczy i użytkowników
- Shutterstock i Adobe Cloud nie pozwalały pobierać ani przesyłać plików
- Trello i Asana nie synchronizowały zadań
- Zoom oraz Microsoft Teams raportowały niestabilne połączenia
Problemy wystąpiły także w usługach Netflixa, Spotify, Discorda, Perplexity AI, Notion, a nawet w systemach McDonald’s, które wykorzystują AWS do obsługi swoich punktów sprzedaży i zamówień.
Kiedy AWS US-EAST-1 przestał działać, fala skutków przetoczyła się przez setki firm i usług, które każdego dnia opierają swoją działalność na chmurze Amazona.
Doskonałym potwierdzeniem skali zdarzenia jest wykres z portalu Downdetector, który zbiera zgłoszenia o problemach w czasie rzeczywistym. Na przedstawionym screenie widać gwałtowny, czerwony pik po godzinie 10:00, kiedy liczba raportów przekroczyła kilka tysięcy w krótkim czasie. To moment, w którym użytkownicy z całego świata zaczęli równocześnie zgłaszać błędy w usługach Amazona. Wykres dosłownie obrazuje chwilę, gdy internet dostał zadyszki.
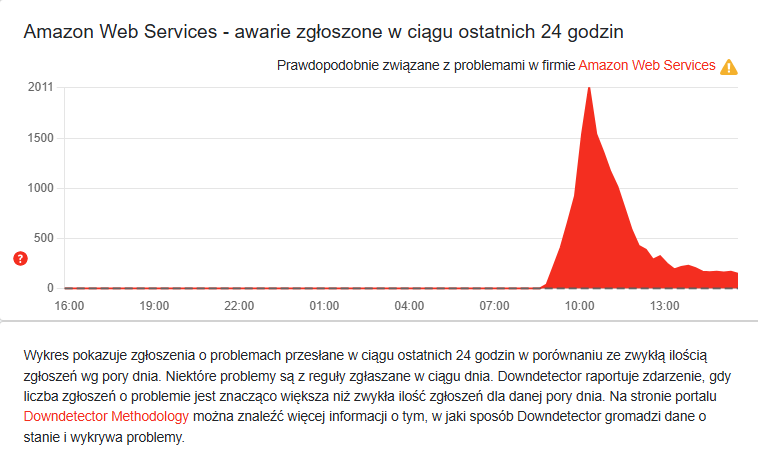
Źródło: https://downdetector.pl/status/aws-amazon-web-services/
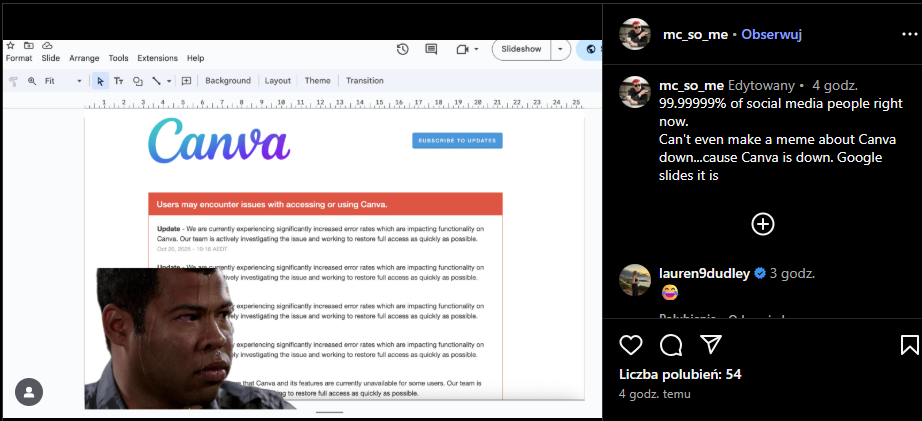
Dla użytkowników – uciążliwość. Dla firm – paraliż pracy. Kampanie stanęły, zespoły nie mogły się komunikować, a twórcy contentu zostali odcięci od swoich narzędzi. W sieci szybko zaczęły krążyć żarty, jak ten byłego Head of Social Media z Ryanair: „Chciałem zrobić mema o tym, że Canva nie działa… ale Canva nie działa”.
 d-tags
d-tags