 d-tags
d-tags


Wysoka pozycja w Google nadal jest cenna, ale znaczy dziś coś innego niż dwa lata temu. W I kwartale 2026 roku 68% wyszukiwań w Google w USA zakończyło się bez jednego kliknięcia (SparkToro na danych Similarweb). Pierwsze miejsce w rankingu coraz częściej oznacza więc nie ruch, tylko obecność w cudzej odpowiedzi.
Zmieniło się przy tym kilka rzeczy naraz: tempo i charakter aktualizacji algorytmu, to, co Google faktycznie ocenia, oraz fakt, że obok klasycznej wyszukiwarki dojrzał drugi ekosystem, który ma własną, równie ruchomą dynamikę. Rozłóżmy te zmiany na konkrety i sprawdźmy, co realnie z nich wynika dla Twojej firmy.
Algorytm zmienia się ciągle, nie skokowo
Google odszedł od modelu kilku zapowiadanych aktualizacji rocznie w stronę zmian niemal ciągłych i coraz gęściej rozłożonych w czasie. Najprościej widać to na oficjalnych danych Google Search Status Dashboard. W całym 2025 roku Google ogłosił cztery aktualizacje rankingowe. W pierwszej połowie 2026 roku, jeszcze przed końcem czerwca, było ich już pięć. Więcej w niespełna sześć miesięcy niż przez cały poprzedni rok.
2025 — cały rok: 4 aktualizacje
| Aktualizacja | Start | Czas trwania |
|---|---|---|
| Core update | 13.03.2025 | 13 dni, 21 godz. |
| Core update | 30.06.2025 | 16 dni, 18 godz. |
| Spam update | 26.08.2025 | 26 dni, 15 godz. |
| Core update | 11.12.2025 | 18 dni, 2 godz. |
I połowa 2026 (do 24.06): 5 aktualizacji
| Aktualizacja | Start | Czas trwania |
|---|---|---|
| Discover update | 05.02.2026 | 21 dni, 17 godz. |
| Spam update | 24.03.2026 | 19 godz., 30 min. |
| Core update | 27.03.2026 | 12 dni, 4 godz. |
| Core update | 21.05.2026 | 11 dni, 21 godz. |
| Spam update | 24.06.2026 | w trakcie |
Źródło: Google Search Status Dashboard (incydenty „Ranking”).
Najwięcej mówią jednak nie same liczby aktualizacji, tylko odstępy i intensywność. W 2025 roku kolejne aktualizacje dzieliło średnio około 91 dni, czyli mniej więcej trzy miesiące oddechu. W pierwszej połowie 2026 ten odstęp skurczył się do średnio około 35 dni, czyli pięciu tygodni, a w marcu spam update i core update wystartowały zaledwie trzy dni po sobie. Innymi słowy: w 2025 strona była pod aktywnym wdrożeniem aktualizacji algorytmu Google około 6 dni w miesiącu, a w okresie luty–czerwiec 2026 już około 12 dni, czyli mniej więcej dwa razy częściej. Klasyczne, „bezpieczne” okna między aktualizacjami praktycznie zniknęły.
Marcowy core update z 2026 roku był przy tym najgwałtowniejszy w historii pomiarów. Pozycje zmieniło 79,5% URL-i z top 3, podczas gdy w grudniu 2025 było to 66,8%, a 24% stron z top 10 wypadło poniżej setnej pozycji. Skala przetasowania dotknęła nawet największych. W marcu 2026 jedną z najgłębszych zapaści widoczności pojedynczej domeny, jakie kiedykolwiek odnotowano, zaliczył YouTube, czyli platforma należąca do samego Google (analiza Amsive, kwiecień 2026). Jeśli algorytm potrafi tak przemeblować własny serwis, rozsądnym założeniem operacyjnym jest, że stabilność pozycji to stan przejściowy, nie punkt docelowy. Przebieg ostatniego wdrożenia opisaliśmy osobno w analizie May 2026 Core Update.
Google ocenia markę, nie pojedynczą stronę
Najważniejsza zmiana jakościowa polega na tym, że algorytm coraz wyraźniej patrzy na całą encję marki, a nie na izolowany adres URL. Po kwietniowym rolloucie wzorzec był czytelny: traciły agregatory, listingi i serwisy żyjące z cudzych treści, a zyskiwały marki, strony oficjalne i źródła nasycone własnymi danymi. Wnioski z naszej praktyki audytowej idą w tę samą stronę. Pojedyncza dobra podstrona bez zaplecza brandowego radzi sobie dziś gorzej, niż radziła rok temu.
Spójnie z tym zmieniły się wytyczne jakościowe. Grudniowy update 2025 rozszerzył wymagania E-E-A-T poza klasyczne branże YMYL, obejmując także obszary traktowane wcześniej łagodniej. Mechanizm dobrze tłumaczy definicja E-E-A-T: nie istnieje żaden pojedynczy „wynik”, są za to tysiące mikrosygnałów (linki, wzmianki, sentyment, struktura domeny), z których systemy uczące się składają obraz tego, czy za treścią stoi realny, wiarygodny podmiot.
Tu jedna rzecz, którą warto powiedzieć wprost, bo branżowe teksty ją mylą. Google nie obniża pozycji treści za to, że powstała z udziałem AI.
John Mueller powiedział to jednoznacznie w listopadzie 2025: systemom nie zależy na tym, kto napisał tekst, liczy się jego użyteczność. Spadki dotykają treści generycznej, masowej, bez ekspertyzy i bez śladu realnego doświadczenia, którą algorytm wyłapuje coraz sprawniej. Praktyczny wniosek jest niewygodny dla części strategii contentowych: budowanie rozpoznawalnej marki jest dziś niezbędnym składnikiem widoczności organicznej, a nie dekoracją wokół niej.
Zero-click to nowa struktura wyników, i jak na nią odpowiedzieć
Brak kliknięcia przestał być wyjątkiem, stał się domyślnym zakończeniem wyszukiwania. Przy AI Overview, według badania Pew Research z lipca 2025, w wynik organiczny klika 8% użytkowników wobec 15% bez AIO, a tylko 1% klika w źródło zacytowane wewnątrz podsumowania. Co czwarta sesja (26%) kończy się zaraz po przeczytaniu odpowiedzi. Na rynku niemieckim, istotnym dla firm wychodzących za granicę, CTR pozycji 1 spada z 27% do 11% (Sistrix, luty 2026).
| Zachowanie użytkownika | Z AI Overview | Bez AI Overview |
|---|---|---|
| Kliknięcie w wynik organiczny | 8% | 15% |
| Kliknięcie w źródło cytowane w AIO | 1% | b.d. |
| Zakończenie sesji po odpowiedzi | 26% | b.d. |
Źródło: Pew Research Center, lipiec 2025 (próba 900 dorosłych w USA).
Sama skala zjawiska w Polsce jest jeszcze umiarkowana. Raport Senuto obejmujący prawie 18 milionów fraz pokazał, że AIO pojawia się dla 24% zapytań, głównie informacyjnych z górnej części lejka. Dla fraz zakupowych Google nadal pokazuje przede wszystkim klasyczne wyniki. I to rozróżnienie jest punktem wyjścia do działania, a nie tylko ciekawostką.
Co z tym zrobić?
- Podziel treści według intencji i traktuj je inaczej. Frazy informacyjne (TOFU) to dziś gra o cytowanie i rozpoznawalność, nie o sesję. Frazy zakupowe (MOFU, BOFU) wciąż prowadzą do klasycznych wyników i realnego ruchu, więc tam nadal walczysz o kliknięcie i konwersję. Inwestowanie w te dwie grupy tak samo to marnowanie budżetu.
- Projektuj treść transakcyjną tak, by AI nie mogło jej zwinąć w trzy zdania. O tym, jak to robić, w sekcji o pięciu cechach stron, które wygrywają.
- Dodaj do raportowania wzrosty wyszukiwań brandowych po publikacjach. Część ruchu zero-click konwertuje się z opóźnieniem: użytkownik widzi Cię w odpowiedzi AI dziś, a wpisuje nazwę marki w Google za tydzień. Bez tego pomiaru wygląda to na stratę, a bywa odroczonym zyskiem.
Jak ten sam mechanizm wygląda po stronie sklepów, rozkładamy w tekście Jak AI Overviews wpłyną na e-commerce. Sama funkcja zadebiutowała w Polsce w marcu 2025 (Google AI Overviews już w Polsce).
Wyszukiwarki AI to ruchome podłoże, nie stały punkt odniesienia
To wątek, który większość tekstów pomija, a który ma realne konsekwencje budżetowe. Łatwo myśleć o AI jako stabilnym środowisku, w którym wybudujemy widoczność i ją potem – no mamy. W rzeczywistości wyszukiwarki AI zmieniają się szybciej niż Google, a zmiany potrafią uderzyć z zaskoczenia.
Pokażę to na danych z naszej praktyki. Przypadek jest zanonimizowany ze względu na NDA, ale mechanizm jest w pełni odtwarzalny i ma czysto biznesowe skutki.
Duży sklep e-commerce. Monitorujemy widoczność w ChatGPT, między innymi poprzez ruch referralowy w GA4. To duża ogólnopolska firma, bardzo mocny brand, więc wejści z AI w GA4 liczymy w dziesiątkach tysięcy – dość duża próbka. Równolegle zaciągamy dane „AI” z Bing Webmaster Tools, bo przez długi czas ChatGPT opierał się na indeksie Binga, więc Bing był rozsądnym przybliżeniem tego, gdzie marka pojawia się w ChatGPT. Przez pierwsze miesiące korelacja między jednym a drugim wynosiła +0,82. Potem, w ciągu kilku miesięcy, ta sama korelacja zjechała do −0,94.
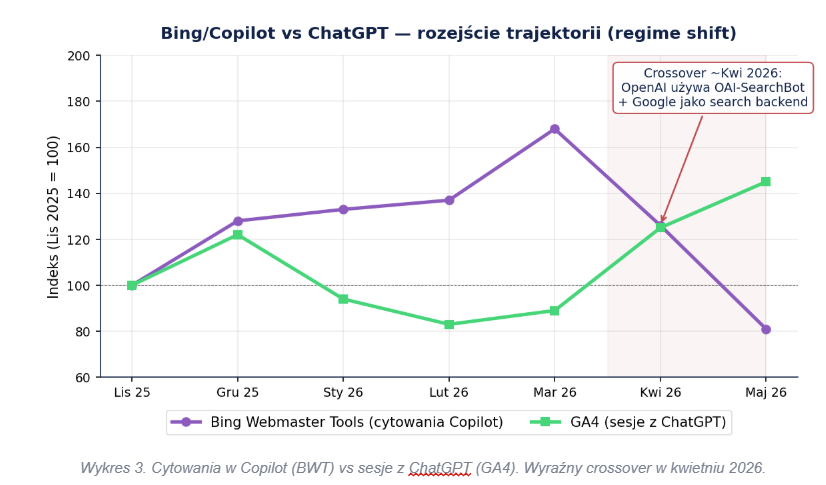
Powód był architektoniczny i dobrze udokumentowany publicznie. ChatGPT przeszedł z indeksu Binga na własny crawler OAI-SearchBot i własny, cache’owany indeks. Już w marcu 2025 analitycy (Scrunch) ostrzegali, że cytowania w ChatGPT i rankingi w Bingu zaczną się rozjeżdżać. Niezależny test to potwierdził: Backlinko opublikowało stronę z wymyślonym terminem, zindeksowaną wyłącznie przez Googlebota, a ChatGPT i tak ją streścił, choć Bing nigdy jej nie widział.
I to nie jest jednorazowy epizod, tylko stała cecha tego środowiska. Kilka liczb i faktów z ostatnich miesięcy:
- Cytowania w AI są nietrwałe. Z dostępnych badań wynika, że około 70% stron cytowanych w AI Overview wymienia się w ciągu 2–3 miesięcy, a rotacja słabo wiąże się z klasycznym rankingiem.
- Sam interfejs zaczął się monetyzować. OpenAI uruchomiło reklamy w ChatGPT na początku 2026 roku, co zmienia ekonomię tego kanału.
- Funkcje pojawiają się i znikają w miesiącach, nie latach. OpenAI uruchomiło zakupy w ChatGPT (Instant Checkout) we wrześniu 2025, rozszerzyło je na wszystkich użytkowników w USA w lutym 2026, a już w marcu 2026 wygasiło tę formę i przeszło na model sklepowych aplikacji (Forrester). Między startem a zwrotem minęło około pół roku.
Wniosek dla firmy jest prosty: widoczności w AI nie da się raz ustawić i zostawić. Podłoże się przesuwa, czasem bez żadnej zapowiedzi, więc każdy pomiar trzeba móc szybko zweryfikować u źródła (logi serwera, ruch referralowy), a nie na jednym wygodnym proxy. Po co to mierzyć, tłumaczy pojęcie AI Visibility: chodzi o to, czy w ogóle istniejesz tam, gdzie zapada decyzja, zanim padnie jakiekolwiek kliknięcie. Jak zacząć od benchmarku, pokazuje audyt AI.
Trik umiera przy kolejnej aktualizacji: lekcja z FAQ schema i llms.txt
Optymalizacja pod doraźny trik, a nie pod realną wartość, to proszenie się o spadek przy następnym ruchu algorytmu. Dwa świeże przykłady pokazują to lepiej niż jakakolwiek teoria.
Pierwszy to FAQ schema. Przez lata standardowy zabieg SEO polegał na doklejaniu sekcji FAQ do niemal każdej strony, żeby zająć więcej miejsca w wynikach rozwijanymi pytaniami. Mechanizm był nadużywany na masową skalę: pytania pod robota, nie pod użytkownika. Google reagował etapami i 7 maja 2026 całkowicie wyłączył wyświetlanie FAQ rich results, kończąc proces zaczęty już w 2023 roku, gdy ograniczył tę funkcję do autorytatywnych witryn rządowych i zdrowotnych. Markup FAQPage nadal jest poprawny i Google wciąż go parsuje, by rozumieć stronę, ale wizualna premia w SERP zniknęła. Kto budował CTR na tym jednym efekcie, stracił go z dnia na dzień.
Drugi przykład to llms.txt, plik reklamowany przez moment jako must-have dla widoczności w AI. Problem w tym, że boty go nie odwiedzają. John Mueller stwierdził wprost (czerwiec 2025), że żaden system AI go nie używa, i porównał go do martwego meta tagu keywords, dodając, że po logach serwera widać, że boty w ogóle o ten plik nie pytają. Gary Illyes potwierdził, że Google go nie wspiera i nie planuje.
Najtwardsze dane przyniosła analiza Ahrefs na 137 tysiącach stron: 97% plików llms.txt nigdy nie zostało odczytanych, a wszystkie kategorie botów AI razem odpowiadały za niespełna 9% zapytań, przy czym najczęściej sięgały po niego narzędzia SEO i serwisy profilujące technologie, a nie wyszukiwarki AI.
Plik, którego boty nie pobierają, nie ma jak wpłynąć na cytowalność. Z perspektywy tych botów nazwanie go llms.txt zamiast jakkolwiek inaczej nie zmienia niczego – możemy wdrożyć np. cats.txt i efekt będzie ten sam.
Wspólny mianownik obu historii: Google i dostawcy AI konsekwentnie wycofują albo ignorują rozwiązania, które stały się celem manipulacji. Wartość, którą trudno zmanipulować (realna ekspertyza, własne dane, czytelna struktura), przetrwała. Zabiegi nastawione na wyłudzenie miejsca w SERP, nie.
Co realnie czytają boty AI i dokąd to zmierza
Boty AI nie potrzebują magicznego pliku, potrzebują strony, którą da się przeczytać, a w przypadku agentów także obsłużyć. I tu dochodzi bardzo ciekawy wątek. W maju 2026 do Lighthouse, a tym samym do PageSpeed Insights, trafiła kategoria Agentic Browsing, oceniająca, jak dobrze strona nadaje się do obsługi przez agentów. Sprawdza między innymi czystość drzewa dostępności, stabilność layoutu, integracje WebMCP oraz obecność llms.txt – sic!
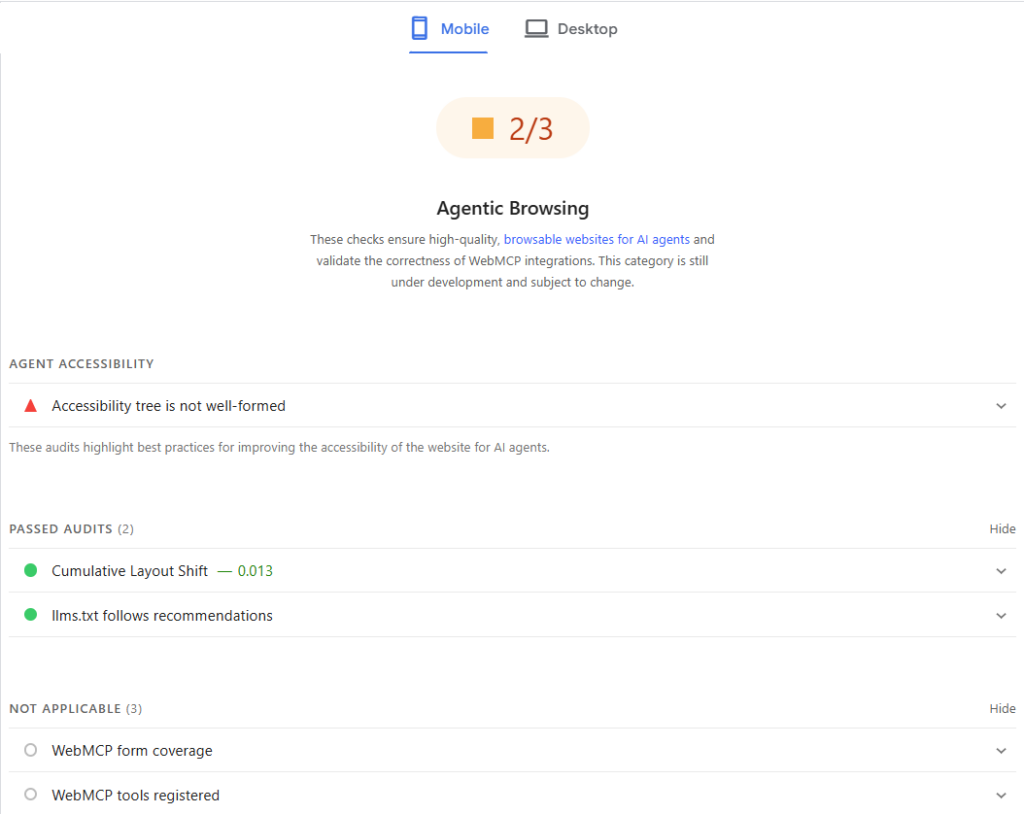
Dwie rzeczy są tu kluczowe. Po pierwsze, kategoria nie ma wyniku 0–100, tylko prosty stosunek zaliczonych testów, i jest oznaczona jako wciąż rozwijana oraz mogąca się zmienić. Po drugie, obecność w tym audycie nie jest czynnikiem rankingowym, co spina się z wcześniejszą uwagą Muellera, że nie wszystko, co jest na stronie, musi wpływać na pozycje. Innymi słowy, to bardzo wstępne testy technologii w toku, a nie ustalony standard.
Warto więc rozdzielić dwie rzeczy, bo łatwo je pomylić. Boty wyszukiwarek AI zasilające cytowania (GPTBot, OAI-SearchBot, PerplexityBot) pobierają zwykle surowy HTML i przeważnie nie renderują JavaScriptu, więc o szansę na cytowanie decyduje ekstrahowalność treści: semantyczny HTML, poprawne nagłówki, prawdziwa tabela zamiast obrazka z tabelą, dane strukturalne. To inny tryb niż agenci, którzy nie tylko czytają, ale klikają i wypełniają formularze.
Ci ostatni opierają się na drzewie dostępności (accessibility tree) jako podstawowym modelu strony, bo jest ono tańsze w przetworzeniu niż surowy HTML czy zrzut ekranu. To kontekst agentowy (agentic browsing), osobny od klasycznego wyszukiwania.
I tu ciekawa asymetria. O llms.txt mówi się w branży bardzo dużo, a o dostępności w kontekście AI prawie wcale, choć to właśnie czyste drzewo dostępności, a nie żaden plik konfiguracyjny, realnie pomaga agentowi poruszać się po stronie. Dodatkowy argument za tymi nudnymi fundamentami: semantyczny HTML, poprawne etykiety i stabilny layout to dokładnie to samo, co od lat poprawia dostępność dla ludzi. Robisz raz, a korzysta i człowiek, i agent.
Google zaczął to nawet mierzyć.
Sam mechanizm przetwarzania treści przez AI jest zresztą znacznie bardziej złożony niż llms.txt czy FAQ. Pojawiają się rozwiązania takie jak WebMCP (sposób, w jaki strona wystawia agentowi swoje formularze i akcje, żeby ten mógł je wywołać zamiast zgadywać po HTML) czy całe protokoły agentic commerce, w których to agent dokonuje zakupu. Tu skala zmian w zakresie rozwiązań oraz standardów jest spora i równie niestabilna. OpenAI i Stripe wystartowały z protokołem zakupowym ACP, Google ze swoim UCP, a Visa i Mastercard z własnymi schematami płatności agentowych.
Jednocześnie Stripe w liście rocznym z 2026 roku przyznał, że agentic commerce zostało „przehype’owane za wcześnie”, i ocenił, że jesteśmy dopiero na pierwszym lub drugim etapie tej zmiany. Wniosek nie brzmi „wdróż wszystko teraz”, tylko „obserwuj i wdrażaj selektywnie, bo połowa z tych standardów dopiero się ustala”.
Jak się ustawić: strona to produkt, nie skończony projekt
Najlepszą odpowiedzią na ruchome podłoże jest budowanie strony, której AI nie umie łatwo zastąpić własnym podsumowaniem, i traktowanie jej jak produktu w ciągłym rozwoju. Pratkyczne przykłady dla pierwszej części daje analiza ponad 400 wygranych i przegranych witryn (Zyppy, kwiecień 2026), w której policzono, które cechy najlepiej przewidują wzrost lub spadek ruchu rok do roku:
Produkt lub usługa
Strona oferuje coś realnego, nie tylko treść do streszczenia.
Możliwa akcja (task completion)
Użytkownik może coś zrobić: kupić, policzyć, skonfigurować, zarezerwować.
Własne zasoby
Dane, badania, narzędzia, których nie ma nikt inny.
Wąski focus tematyczny
Spójny obszar ekspertyzy zamiast łapania wszystkich fraz.
Silny brand
Marka, której użytkownik szuka świadomie i do której wraca.
Dwie pierwsze cechy to dokładnie widoczny cel strony i możliwość wykonania na niej akcji. Czysto informacyjny artykuł „co to jest X” jest najłatwiejszy do zwinięcia w trzy zdania AI Overview. Strona z kalkulatorem, konfiguratorem, własnym zestawieniem cen albo realną funkcją transakcyjną daje powód, żeby wejść i zostać, a jednocześnie jest tym, co protokoły agentowe próbują dziś wystawić agentom do obsługi. Buduje się przy tym jeden spójny fundament dla użytkownika, klasycznego SEO i AI naraz.
Prosty przykład – zrobiony przed kilku laty kalkulator współczynnika konwersji, który wdrożyliśmy na Delante, a na którym nic się nie dzieje i nie jest promowany w żaden sposób rok do roku generuje coraz większy ruch. Mimo, że narzędzie jest banalnie proste i można by to policzyć ot choćby w arkuszu kalkulacyjnym.




