 d-tags
d-tags

 (ilość głosów: 12, średnia: 4,42 na 5)
(ilość głosów: 12, średnia: 4,42 na 5)- Robots.txt. Co to jest?
- Miejsca, których robot nie powinien indeksować
- Robots.txt to tylko zalecenia
- Robots.txt generator, czyli jak stworzyć plik?
- Zasady wprowadzania oznaczeń w robots.txt
- Gdzie umieścić plik robots.txt?
- Robots.txt. Podsumowanie
Robots.txt. Co to jest?
Plik robots txt wykorzystujemy do komunikacji z robotami internetowymi . To właśnie tego prostego pliku tekstowego roboty poszukują jako pierwszego, gdy dotrą na naszą witrynę. Składa się on z kombinacji komend zgodnych ze standardem Robots Exclusion Protocol - “językiem” zrozumiałym dla botów. Dzięki robots.txt możemy wpłynąć na kierunek ich ruchu, ograniczając dostęp do zasobów, które w kontekście wyników wyszukiwania są zbędne. Mogą być to pliki graficzne, style, skrypty, a co najważniejsze - określone podstrony naszej witryny.Miejsca, których robots.txt nie powinien indeksować
Strony internetowe już dawno przestały być prostymi plikami zawierającymi tylko i wyłącznie treść w postaci tekstu. Zwłaszcza sklepy internetowe posiadają często tysiące podstron, wśród których pewna część nie ma żadnej wartości w kontekście wyników wyszukiwania, a w najgorszym wypadku spowoduje duplikację treści (jakie to strony i jak sobie z nimi radzić dowiesz się z naszego wpisu o duplikacji treści: Duplikacja treści – jak sobie z nią radzić?). Elementy, takie jak sklepowy koszyk, wewnętrzna wyszukiwarka, procedura składania zamówienia czy panel użytkownika, nie powinny być dostępne dla robotów. Dużo większe jest prawdopodobieństwo, że ze względu na swoją konstrukcję, wprowadzą zbędne zamieszanie, niż to, że poprawią naszą widoczność w SERP-ach. Warto blokować również kopie podstron wykonywane przez CMS, które zwiększają duplikację wewnętrzną strony.Komentarz specjalisty
Sprawdź dokładnie, które strony decydujesz się blokować. Jeśli roboty nie zidenksują którejś z ważnych dla Ciebie podstron, to może to znacznie wpłynąć na pozycjonowanie całej witryny.

Przemek Jaskierski
SEO Specialist
Zachowaj szczególną ostrożność!
Tworząc reguły kierujące ruchem botów indeksujących, należy dobrze znać strukturę strony internetowej. Istnieje bowiem ryzyko, że jedną komendą zablokujemy im dostęp do całości witryny lub ważnych dla nas treści. Rezultat będzie więc odwrotny do zamierzonego - znikniemy z wyników wyszukiwania.Robots.txt to tylko zalecenia
Wspomniany wcześniej protokół komunikacji to tzw. system honorowy. Robot może podążać za naszymi zaleceniami, ale nie możemy mu w ten sposób naszej woli narzucić. Dzieje się tak z różnych powodów. Przede wszystkim, robot Google - czyli Googlebot - nie jest jednym botem przeglądającym strony internetowe. O ile twórcy największej na świecie wyszukiwarki zapewniają, że ich wysłannik uzna nasze zalecenia, o tyle inne już nie muszą. Konkretny adres URL może również zostać zaindeksowany, jeśli link do niego pojawi się na innej, indeksowanej witrynie. W zależności od potrzeb, można się przed taką sytuacją uchronić na kilka sposobów. Przykładem może być tutaj metatag “noindex” lub nagłówek HTTP “X-Robots-Tag”. Prywatne dane zawsze warto zabezpieczyć hasłem - roboty nie potrafią sobie z nim poradzić. Dlatego też w kontekście tego pliku mówimy o ukrywaniu danych, a nie ich kasowaniu z indeksu wyszukiwarki.Robots.txt generator, czyli jak stworzyć plik?
W internecie znaleźć można wiele generatorów pliku robots (robots.txt generator), a systemy CMS wyposażone są często w mechanizm wspierający użytkownika w tworzeniu takiego pliku. Niewielkie są szanse, że pojawi się konieczność ręcznego przygotowania instrukcji. Warto jednak poznać składnię protokołu, czyli reguły i komendy jakie możemy wydać robotom indeksującym.Konstrukcje
Tworzymy plik tekstowy robots.txt. Według zaleceń Google system kodowania znaków to ASCII lub UTF-8. Generalnie - powinien być jak najprostszy. Do wydawania poleceń używamy kilku kluczowych słów zakończonych dwukropkiem, tworząc reguły dostępu. User-agent: - określa adresata komendy. Wpisujemy tutaj nazwę bota indeksującego. W internecie znajdziemy obszerną bazę nazw (http://www.robotstxt.org/db.html), najczęściej jednak chcemy się komunikować z robotem Google - czyli wspomnianym już Googlebot lub wszystkimi na raz - używamy wówczas gwiazdki “*”. Przykładowo więc, dla bota Google pierwsza linijka reguł wygląda następująco:User-agent: Googlebot
Disallow: - po tym słowie podajemy adres, którego boty nie powinny skanować. Najpopularniejsze metody to ukrywanie zawartości całych katalogów poprzez wpisanie ścieżki dostępu zakończonej symbolem “/”, np:
Disallow: /zablokowany/
lub plików:
Disallow: /katalog/zablokowanyplik.html
Allow: - jeśli wewnątrz ukrytego katalogu znajduje się zawartość, którą chcielibyśmy udostępnić robotom do przeskanowania, ścieżkę do niej podajemy po słowie Allow:
Allow: /zablokowany/odblokowanykatalog/
Allow: /zablokowany/inne/odblokowanyplik.html
Sitemap: - po tym słowie określamy ścieżkę do mapy witryny. Element ten nie jest jednak konieczny do prawidłowego działania pliku robots.txt. Przykładowo:
Sitemap: http://www.mojswietnyadres.com/sitemap.xml

Zasady wprowadzania oznaczeń w robots.txt
Reguła domyślna
Przede wszystkim warto pamiętać, że domyślną instrukcją dla robotów indeksujących jest zgoda na przeskanowanie całej witryny. Tak więc, jeśli plik robots.txt ma mieć postać właśnie tej reguły:User-agent: *
Allow: /
to nie mamy obowiązku umieszczenia go w katalogu strony. Boty będą ją skanować według własnego uznania. Warto jednak taki plik zamieścić, aby uniknąć ewentualnych błędów podczas jej analizy.
Wielkość liter
Może to być zaskoczeniem, ale roboty są w stanie rozpoznawać małe i wielkie litery. Zatem plik.php i Plik.php będą dla nich dwoma różnymi adresami.Potęga gwiazdki
Inną, praktyczną funkcjonalnością jest operator wieloznaczny, czyli wspomniana już wcześniej gwiazdka - *. W Robots Exclusion Protocol jest to informacja, że w danym miejscu może się pojawić dowolny ciąg znaków, nieograniczonej długości (również zerowej). Przykładowo, reguła:Disallow: /*/plik.html
będzie dotyczyć zarówno pliku znajdującego się w lokalizacji:
/katalog1/plik.html
jak i tego w folderze:
/folder1/folder2/folder36/plik.html
Gwiazdkę możemy wykorzystać w inny sposób. Instrukcja w której umieścimy ją przed konkretnym rozszerzeniem pliku, pozwala nam odnieść regułę do wszystkich plików tego typu. Przykładowo:
Disallow: /*.php
odniesie się do wszystkich plików .php na naszej stronie (z wyjątkiem ścieżki “/”, nawet jeśli prowadzi to pliku o rozszerzeniu .php), a reguła:
Disallow: /folder1/test*
do wszystkich plików i katalogów w folderze folder1 ze znakami “test” na początku.
Zakończenie ciągu znaków
Warto również wiedzieć o istnieniu operatora “$” który oznacza koniec adresu. Tym sposobem, dla przykładu korzystając z reguły:>User-agent: *
Disallow: /folder1/
Allow: /folder1/*.php$
zalecimy, by boty nie indeksowały zawartości katalogu folder1, ale jednocześnie pozwolimy na skanowanie plików .php w jego wnętrzu. Ścieżki zawierające np. przesłane parametry typu:
http://mojastrona.pl/katalog1/strona.php?page=1
nie będą sprawdzane przez boty. Tego typu kwestię można jednak łatwo rozwiązać przy użyciu linków kanonicznych.
Komentarze
Jeżeli powstały plik i nasza strona są dość złożone, warto dodać komentarze wyjaśniające nasze decyzje. Jest to bardzo proste - wystarczy dodać “#” na początku linii. Roboty podczas swojej pracy pominą jej zawartość.Kilka przykładów
Regułę, która odblokowuje dostęp do wszystkich plików, przytoczyliśmy wcześniej. Warto również poznać tę, która spowoduje że boty opuszczą naszą witrynę.User-agent: *
Disallow: /
Jeśli więc nasza strona nie jest w ogóle widoczna w wyszukiwarce, warto sprawdzić czy w jej pliku robots.txt nie znalazł się ten zapis.
Ciekawym przykładem gotowego pliku robots.txt może być poniższy, znajdujący się na stronie sklepu internetowego:
 Zawiera on zbiór wszystkich wspomnianych wcześniej konstrukcji oprócz niewymaganego Sitemap. Reguły kierowane są do wszystkich botów. Zablokowano np. katalog “
Zawiera on zbiór wszystkich wspomnianych wcześniej konstrukcji oprócz niewymaganego Sitemap. Reguły kierowane są do wszystkich botów. Zablokowano np. katalog “environment” jednocześnie dopuszczając roboty do ścieżki “/environment/cache/images/. Niedostępne dla wyszukiwarki będą tutaj również m.in. koszyk, strony logowania, kopie treści (index, full) a także wewnętrzna opcja szukaj czy dodawanie komentarzy.
Gdzie umieścić plik robots.txt?
Stworzyliśmy już plik tekstowy zgodny ze wszystkimi standardami. Jedyne co nam pozostało, to przesłać go na serwer. Tutaj zasada jest bardzo prosta. Musi się on znaleźć w katalogu głównym hosta naszej strony internetowej. Każda inna lokalizacja spowoduje, że boty go nie odnajdą. Tak więc przykładowy adres to:http://mojastrona.pl/robots.txt
Jeżeli posiadamy kilka wersji adresu, np. z http, https, www i bez www, warto zastosować odpowiednie przekierowania do jednej, głównej domeny. Dzięki temu będą się one indeksować poprawnie.
Informacje dla Google
Prawidłowo zlokalizowany plik zostanie rozpoznany przez roboty wyszukiwarki. Jednak możemy im w tym dodatkowo pomóc. Google umożliwia użytkownikom narzędzia Search Console przetestowanie obecnego pliku, sprawdzenie działania planowanych modyfikacji i zgłoszenie nowego pliku robots.txt. Linki z oficjalnej dokumentacji Google kierują do starej wersji GSC, więc i my z niej skorzystamy. [caption id="attachment_7189" align="aligncenter" width="750"]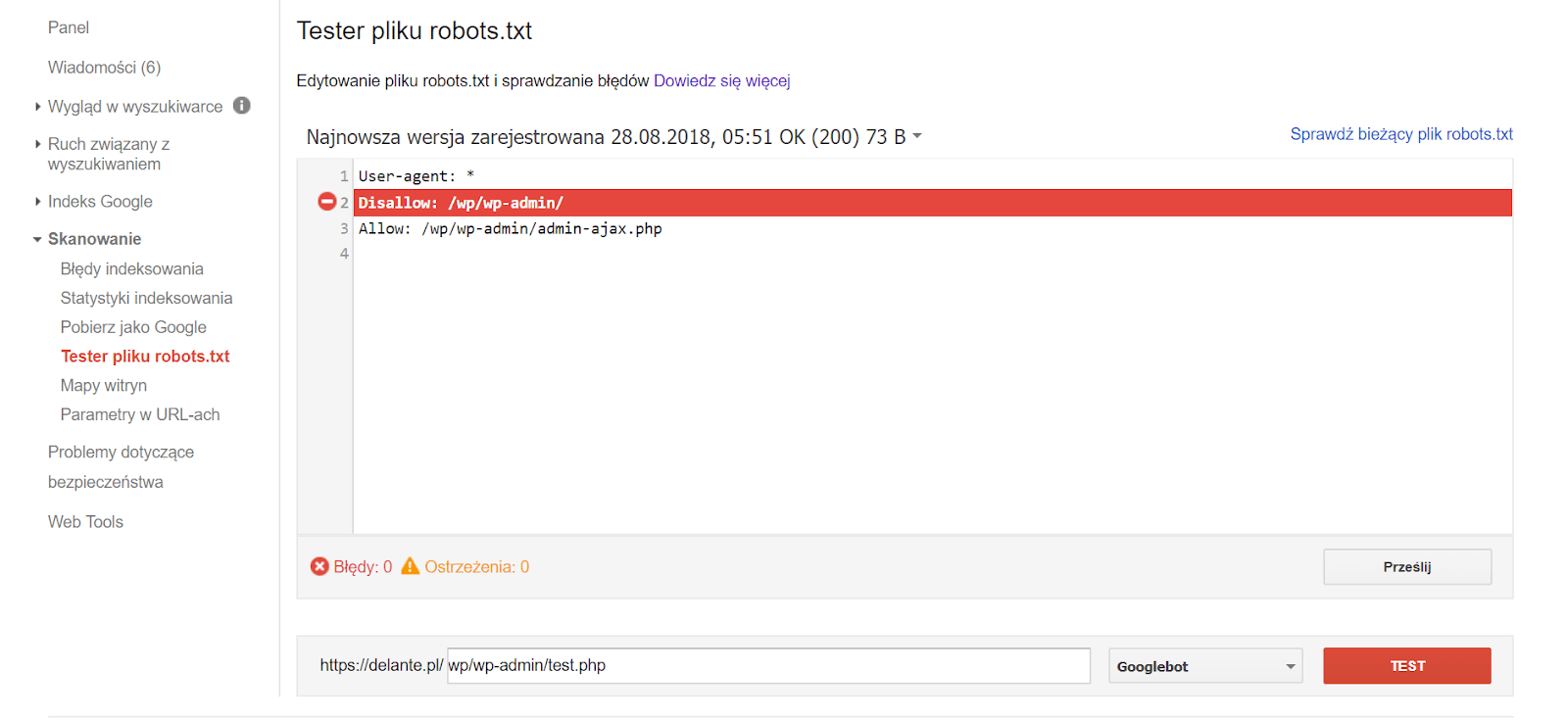 źródło: https://www.google.com/webmasters/tools/robots-testing-tool[/caption]
Korzystając z tego narzędzia możemy sprawdzić, czy konkretne elementy naszej witryny są widoczne dla robotów. Dla przykładu adres /wp/wp-admin/test.php będzie dla nich niedostępny ze względu na ograniczenie nałożone linijką oznaczoną na czerwono. Jeśli zaktualizowaliśmy plik robots.txt możemy o tym poinformować Google korzystając z opcji “Prześlij”, prosząc o ponowną weryfikację.
źródło: https://www.google.com/webmasters/tools/robots-testing-tool[/caption]
Korzystając z tego narzędzia możemy sprawdzić, czy konkretne elementy naszej witryny są widoczne dla robotów. Dla przykładu adres /wp/wp-admin/test.php będzie dla nich niedostępny ze względu na ograniczenie nałożone linijką oznaczoną na czerwono. Jeśli zaktualizowaliśmy plik robots.txt możemy o tym poinformować Google korzystając z opcji “Prześlij”, prosząc o ponowną weryfikację.


